According to Flynn’s taxonomy SIMD refers to a computer architecture that can process multiple data streams with a single instruction (i.e. “Single Instruction stream, Multiple Data streams”). There are different taxonomies, and within those several different sub-categories and architectures that classify as “SIMD”.
In this post, however, I refer to packed SIMD ISA:s, i.e. the type of SIMD instruction set architecture that is most common in contemporary consumer grade CPU:s. More specifically, I refer to non-predicated packed SIMD ISA:s where the details of packed SIMD processing is exposed to the software environment.
Packed SIMD
The common trait of packed SIMD architectures is that several data elements are packed into a single register of a fixed width. Here is an example of possible configurations of a packed 128 bits wide SIMD register:
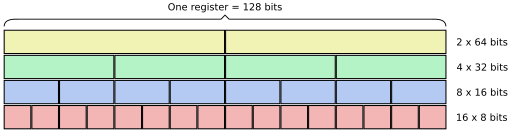
For instance, a 128-bit register can hold sixteen integer bytes or four single precision floating-point values.
This type of SIMD architecture has been wildly popular since the mid 1990s, and some packed SIMD ISA:s are:
- x86: MMX, 3DNow!, SSE, SSE2, …, and AVX, AVX2, AVX-5121
- ARM: ARMv6 SIMD, NEON
- POWER: AltiVec (a.k.a. VMX and VelocityEngine)
- MIPS: MDMX, MIPS-3D, MSA, DSP
- SPARC: VIS
- Alpha: MVI
1 AVX and later x86 SIMD ISA:s (especially AVX-512) incorporate features from vector processing, making them packed SIMD / vector processing hybrids (thus some of the aspects discussed in this article do not fully apply).
The promise of all those ISA:s is increased data processing performance, since each instruction executes several operations in parallel. However, there are problems with this model.
Flaw 1: Fixed register width
Since the register size is fixed there is no way to scale the ISA to new levels of hardware parallelism without adding new instructions and registers. Case in point: MMX (64 bits) vs SSE (128 bits) vs AVX (256 bits) vs AVX-512 (512 bits).
Adding new registers and instructions has many implications. For instance, the ABI must be updated, and support must be added to operating system kernels, compilers and debuggers.
Another problem is that each new SIMD generation requires new instruction opcodes and encodings. In fixed width instruction sets (e.g. ARM) this may prohibit any new extensions, since there may not be enough opcode slots left for adding the new instructions. In variable width instruction sets (e.g. x86) the effect is typically that instructions get longer and longer (effectively hurting code density). Paradoxically each new SIMD generation essentially renders the previous generations redundant (except for supporting binary backwards compatibility), so a large number of instructions are wasted without adding much value.
Finally, any software that wants to use the new instruction set needs to be rewritten (or at least recompiled). What is worse, software developers often have to target several SIMD generations, and add mechanisms to their programs that dynamically select the optimal code paths depending on which SIMD generation is supported.
Flaw 2: Pipelining
The packed SIMD paradigm is that there is a 1:1 mapping between the register width and the execution unit width (this is usually required to achieve reasonable performance for instructions that mix inputs from several lanes). At the same time many SIMD operations are pipelined and require several clock cycles to complete (e.g. floating-point arithmetic and memory load instructions). The side effect of this is that the result of one SIMD instruction is not ready to be used until several instructions later in the instruction stream.
Consequently, loops have to be unrolled in order to avoid stalls and keep the pipeline busy. This can be done in advanced (power hungry) hardware implementations with register renaming and speculative out-of-order execution, but for simpler (usually more power efficient) hardware implementations loops have to be unrolled in software. Many software developers and compilers aiming to support both in-order and out-of-order processors simply unroll all SIMD loops in software.
However, loop unrolling hurts code density (i.e. makes the program binary larger), which in turn hurts instruction cache performance (fewer program segments fit in the instruction cache, which reduces the cache hit ratio).
Loop unrolling also increases register pressure (i.e. more registers must be used in order to keep the state of multiple loop iterations in registers), so the architecture must provide enough SIMD registers to avoid register spilling.
Flaw 3: Tail handling
When the number of array elements that are to be processed in a loop is not a multiple of the number of elements in the SIMD register, special loop tail handling needs to be implemented in software. For instance if an array contains 99 32-bit elements, and the SIMD architecture is 128 bits wide (i.e. a SIMD register contains four 32-bit elements), 4*24=96 elements can be processed in the main SIMD loop, and 99-96=3 elements need to be processed after the main loop.
This requires extra code after the loop for handling the tail. Some architectures support masked load/store that makes it possible to use SIMD instructions to process the tail, while a more common scenario is that you have to use scalar (non-SIMD) instructions to implement the tail (in the latter case there may be problems if scalar and SIMD instructions have different capabilities and/or semantics, but that is not an issue with packed SIMD per se, just with how some ISA:s are designed).
Usually you also need extra control logic before the loop. For instance if the array length is less than the SIMD register width, the main SIMD loop should be skipped.
The added control logic and tail handling code hurts code density (again reducing the instruction cache efficiency), and adds extra overhead (and is generally awkward to code).
Alternatives
One alternative to packed SIMD that addresses all of the flaws mentioned above is a Vector Processor. Perhaps the most notable vector processor is the Cray-1 (released 1975), and it has served as an inspiration for a new generation of instruction set architectures, including RISC-V RVV.
Several other (perhaps less known) projects are pursuing a similar vector model, including Agner Fog’s ForwardCom, Robert Finch’s Thor2021 and my own MRISC32. An interesting variant is Libre-SOC (based on OpenPOWER) and its Simple-V extension that maps vectors onto the scalar register files (which are extended to include some 128 registers each).
ARM SVE is a predicate-centric, vector length agnostic ISA that addresses many of the traditional SIMD issues.
A completely different approach is taken by Mitch Alsup’s My 66000 and its Virtual Vector Method (VVM), which transforms scalar loops into vectorized loops in hardware with the aid of special loop decoration instructions. That way it does not even have to have a vector register file.
Another interesting architecture is the Mill, which also has support for vectors without packed SIMD.
Examples
Edit: This section was added on 2021-08-19 to provide some code examples that show the difference between packed SIMD and other alternatives, and extended on 2023-05-31 with RISC-V RVV and ARM SVE examples and more comments.
A simple routine from BLAS is saxpy, which computes z = a*x + y, where a is a constant, x and y are arrays, and the “s” in “saxpy” stands for single precision floating-point.
// Example C implementation of saxpy:
void saxpy(size_t n, float a, float* x, float* y, float* z)
{
for (size_t i = 0; i < n ; i++)
z[i] = a * x[i] + y[i];
}Below are assembler code snippets that implement saxpy for different ISA:s.
Packed SIMD (x86_64 / SSE)
saxpy:
test rdi, rdi
je .done
cmp rdi, 8
jae .at_least_8
xor r8d, r8d
jmp .tail_2_loop
.at_least_8:
mov r8, rdi
and r8, -8
movaps xmm1, xmm0
shufps xmm1, xmm0, 0
lea rax, [r8 - 8]
mov r9, rax
shr r9, 3
add r9, 1
test rax, rax
je .dont_unroll
mov r10, r9
and r10, -2
neg r10
xor eax, eax
.main_loop:
movups xmm2, xmmword ptr [rsi + 4*rax]
movups xmm3, xmmword ptr [rsi + 4*rax + 16]
mulps xmm2, xmm1
mulps xmm3, xmm1
movups xmm4, xmmword ptr [rdx + 4*rax]
addps xmm4, xmm2
movups xmm2, xmmword ptr [rdx + 4*rax + 16]
addps xmm2, xmm3
movups xmmword ptr [rcx + 4*rax], xmm4
movups xmmword ptr [rcx + 4*rax + 16], xmm2
movups xmm2, xmmword ptr [rsi + 4*rax + 32]
movups xmm3, xmmword ptr [rsi + 4*rax + 48]
mulps xmm2, xmm1
mulps xmm3, xmm1
movups xmm4, xmmword ptr [rdx + 4*rax + 32]
addps xmm4, xmm2
movups xmm2, xmmword ptr [rdx + 4*rax + 48]
addps xmm2, xmm3
movups xmmword ptr [rcx + 4*rax + 32], xmm4
movups xmmword ptr [rcx + 4*rax + 48], xmm2
add rax, 16
add r10, 2
jne .main_loop
test r9b, 1
je .tail_2
.tail_1:
movups xmm2, xmmword ptr [rsi + 4*rax]
movups xmm3, xmmword ptr [rsi + 4*rax + 16]
mulps xmm2, xmm1
mulps xmm3, xmm1
movups xmm1, xmmword ptr [rdx + 4*rax]
addps xmm1, xmm2
movups xmm2, xmmword ptr [rdx + 4*rax + 16]
addps xmm2, xmm3
movups xmmword ptr [rcx + 4*rax], xmm1
movups xmmword ptr [rcx + 4*rax + 16], xmm2
.tail_2:
cmp r8, rdi
je .done
.tail_2_loop:
movss xmm1, dword ptr [rsi + 4*r8]
mulss xmm1, xmm0
addss xmm1, dword ptr [rdx + 4*r8]
movss dword ptr [rcx + 4*r8], xmm1
add r8, 1
cmp rdi, r8
jne .tail_2_loop
.done:
ret
.dont_unroll:
xor eax, eax
test r9b, 1
jne .tail_1
jmp .tail_2Notice how the packed SIMD code contains a 4x unrolled version of the main SIMD loop and a scalar tail loop. It also contains a setup phase (the first 20 instructions) that should not have a huge performance impact for long arrays, but for short arrays the setup code adds unnecessary overhead.
Unfortunately, this kind of manual setup + unrolling + tail handling code uses up unnecessarily large chunks of the instruction cache of a CPU core.
This demonstrates flaws 2 & 3 described above. Flaw 1 is actually also present, since you need to have multiple implementations for optimal performance on all CPU:s. E.g. in addition to the SSE implementation above, you would also need AVX2 and AVX-512 implementations, and switch between them at run time depending on CPU capabilities.
Vector (MRISC32)
saxpy:
bz r1, 2f ; Nothing to do?
getsr vl, #0x10 ; Query the maximum vector length
1:
minu vl, vl, r1 ; Define the operation vector length
sub r1, r1, vl ; Decrement loop counter
ldw v1, [r3, #4] ; Load x[] (element stride = 4 bytes)
ldw v2, [r4, #4] ; Load y[]
fmul v1, v1, r2 ; x[] * a
fadd v1, v1, v2 ; + y[]
stw v1, [r5, #4] ; Store z[]
ldea r3, [r3, vl*4] ; Increment x pointer
ldea r4, [r4, vl*4] ; Increment y pointer
ldea r5, [r5, vl*4] ; Increment z pointer
bnz r1, 1b
2:
retUnlike the packed SIMD version, the vector version is much more compact since it handles unrolling and the tail in hardware. Also, the setup code is minimal (just 1-2 instructions).
The GETSR instruction is used for querying the implementation defined maximum vector length (i.e. the number of 32-bit elements that a vector register can hold). The VL register defines the vector length (number of elements to process) for the vector operations. During the last iteration, VL may be less than the maximum vector length, which takes care of the tail.
Load and store instructions take a “byte stride” argument that defines the address increment between each vector element, so in this case (stride=4 bytes) we load/store consecutive single-precision floating-point values. The FMUL and FADD instructions operate on each vector element separately (either in parallel or in series, depending on the hardware implementation).
Vector (RISC-V V extension)
Code and comments graciously provided by Bruce Hoult:
saxpy:
vsetvli a4, a0, e32,m8, ta,ma // Get vector length in items, max n
vle32.v v0, (a1) // Load from x[]
vle32.v v8, (a2) // Load from y[]
vfmacc.vf v8, fa0, v0 // y[] += a * x[]
vse32.v v8, (a3) // Store to z[]
sub a0, a0, a4 // Decrement item count
sh2add a1, a4, a1 // Increment x pointer
sh2add a2, a4, a2 // Increment y pointer
sh2add a3, a4, a3 // Increment z pointer
bnez a0, saxpy
retThe vector length agnostic RISC-V vector ISA enables more efficient code and a much smaller code footprint than packed SIMD, just like MRISC32. RISC-V also has a fused multiply-add instruction (VFMACC) that further shortens the code (FMA is planned to be added to the MRISC32 ISA in the future).
A few notes about the use of VSETVLI (set vector length) in the example:
- e32,m8 means 32 bit data items, use 8 vector registers at a time e.g. v0-v7, v8-v15 effectively hardware unrolling by 8x and processing e.g. 32 items at a time with 128 bit vector registers. The last iteration can process anywhere from 1 to 32 items (or 0 if n is 0).
- ta,ma means we don’t care how masked-off elements are handled (we aren’t using masking), and don’t care how unused tail elements are handled on the last iteration.
The code actually correctly handles n=0 (empty array), so unless we expect that to be very common it would be silly to handle it specially and slow everything else down by one instruction.
Predicated SIMD (ARM SVE)
saxpy:
mov x4, xzr // Set start index = 0
dup z0.s, z0.s[0] // Convert scalar a to a vector
1:
whilelo p0.s, x4, x0 // Set predicate [index, n)
ld1w z1.s, p0/z, [x1, x4, lsl 2] // Load x[] (predicated)
ld1w z2.s, p0/z, [x2, x4, lsl 2] // Load y[] (predicated)
fmla z2.s, p0/m, z0.s, z1.s // y[] += a * x[] (predicated)
st1w z2.s, p0, [x3, x4, lsl 2] // Store z[] (predicated)
incw x4 // Increment start index
b.first 1b // Loop if first bit of p0 is set
retAs can be seen, a SIMD ISA with proper predication/masking support can easily do tail handling in hardware, and thus the code is very similar to that of a vector processor. The key is the use of a predication register (p0), which is initialized with a binary true/false mask using the WHILELO instruction, and later used for all the vector operations to mask out vector elements that should not be part of the current iteration (effectively only happens in the last iteration, which takes care of the tail).
Also note how the code is register width agnostic (WHILELO and INCW handle that for you).
Virtual Vector Method (My 66000)
saxpy:
beq0 r1,1f ; Nothing to do?
mov r8,#0 ; Loop counter = 0
vec r9,{} ; Start vector loop
lduw r6,[r3+r8<<2] ; Load x[]
lduw r7,[r4+r8<<2] ; Load y[]
fmacf r6,r6,r2,r7 ; x[] * a + y[]
stw r6,[r5+r8<<2] ; Store z[]
loop ne,r8,r1,#1 ; Increment counter and loop
1:
retThe Virtual Vector Method (VVM) is a novel technique invented by Mitch Alsup, and it allows vectorization without a vector register file. As you can see in this example only scalar instructions and references to scalar register names (“r*“) are used. The key players here are the VEC and LOOP instructions that turn the scalar loop into a vector loop.
Essentially the VEC instruction marks the top of the vectorized loop (r9 stores the address of the loop start, which is implicitly used by the LOOP instruction later). All instructions between VEC and LOOP are decoded and analyzed once and are then performed at the capabilities of the hardware. In this case most register identifiers (r1, r3, r4, r5, r6, r7, r8) are used as virtual vector registers, whereas r2 is used as a scalar register. The LOOP instruction increments the counter by 1, compares it to r1, and repeats the loop as long as the condition, not equal (“ne”), is met.
Further reading
Also see: SIMD considered harmful (D. Patterson, A. Waterman, 2017)
I was prepared to criticize this article, but the conclusion changed my mind. Consider looking at systolic arrays; wholly break free of the von Neumann style. Read “Can Programming Be Liberated from the von Neumann Style?” by John Backus.
As for tail handling, my solution would be to set the filler to a safe dummy value, to be ignored.
You can work around the tail handling problems if you have full control over the data structures etc. Unfortunately that’s a luxury that the compiler auto-vectorizer does not have when compiling generic code. E.g. see: https://godbolt.org/z/aWjMcj7eo
Also, the fact that you have to think about these things, however easy the workaround is, is still a sign of a flaw IMO.
I figured that would be the optimization-retardant there. It’s almost not fair to blame this hardware for language idiocy, but we’d be using much better hardware were it not the case.
I enjoy using APL, and I’m to understand Dyalog APL has no issue effectively using these facilities, but it’s a language actually suited to it.
Unfortunately it’s not a language defect. The SSE SIMD code must look like that in order to run at optimal performance, regardless of which language was used to describe the loop. It’s a direct result of #2 and #3 above.
this “works” perfectly… right up until the moment where you want to STORE the data. remember: most processing is of the type “LOAD COMPUTE STORE”. in SIMD terms, the LOAD width == the COMPUTE width == the STORE width. at that point, the plan that you suggest will completely destroy (corrupt) memory. in some scenarios you won’t even *get* to the LOAD point because the LOAD overlaps a memory boundary (or overruns the end of memory), causing at best an unnecessary VM page fault and at worst termination of the program.
SIMD should basically be unceremoniously clubbed to death and buried as the worst and most deeply embarrassing mistake in the history of mainstream computing of the past 50 years.
I think he is referreing to a standard solution in SIMD programming: Design your data types so that all SIMD accesses are 1) aligned to SIMD width boundaries, and 2) always a multiple of the SIMD width. This way you need never care about page crossings, and you can treat the tail as “don’t care”. Obviously this is quite intrusive (e.g. you need to use custom memory allocations etc), and it’s not something that could be used by a compiler doing auto-vectorization for instance.
Flaw 4: Chaining between the elements within the Packed SIMD operation is fundamentally impossible *by design*. this means that when getting better “performance” (because the SIMD width is longer), the data processing latency also increases. this is fundamentally unfixable.
VVM looks very interesting, but I can’t find too much information about the “My 66000” ISA. I’d like to know more, especially about the implementation. Do you (or anyone else) know where I can find more about it?
It does, doesn’t it. The My 66000 inventor, CPU architect rock star and veteran Mitch Alsup, frequents the comp.arch newsgroup. He usually gladly shares information there, and if you ask nicely he will probably send you the ISA documentation.
1. Where did MAD/FMA go?
2. You probably can remove .dont_unroll if you add attribute aligned
3. If you know properties of n you can inform compiler about it with conditional __builtin_unreachable