Lately I have taken some interest in the hardware and software of C++ build servers. One of the things that I have noticed is that there is a significant performance difference between Windows and Linux machines for common build tasks, such as cloning a git repository, running CMake and caching build results.
Some of these differences can obviously by explained by the fact that the software was originally designed and optimized for Linux (which is especially true for git), but surely there must be underlying differences in the operating systems that contribute to this too.
To get a clearer picture, I set out to benchmark some typical core primitives of operating systems. This includes:
- Process and thread creation.
- File creation.
- Memory allocation.
These are things that are used heavily by software build tool chains, as well as by many other softwares (e.g. VCS clients/servers, web servers, etc).
The benchmark suite
I wrote a set of simple micro benchmarks in plain C. You can find the source code on GitLab. I have built and run the benchmark programs on Linux, Windows and macOS, and they should be very portable and run on most Unix-like operating systems.
Pre-built binaries for Windows (64-bit, compiled with GCC): osbench-win64-20170529.zip
The test systems
| Name | OS | CPU | Disk |
|---|---|---|---|
| Linux-i7x4 | Ubuntu 16.04 | i7-6820HQ, 4-core, 2.7GHz | 256GB SSD (SATA) |
| Linux-i7x8 | Ubuntu 16.10 | i7-6900K, 8-core, 3.2GHz | 1TB SSD (NVMe) |
| Linux-AMDx8 | Fedora 25 | Ryzen 1800X, 8-core, 3.6GHz | 250GB SSD (NVMe) |
| RaspberryPi | Raspbian Jessie | ARMv7, 4-core, 1.2GHz | 32GB MicroSD |
| MacBookPro | macOS 10.12.4 | i5-6360U, 2-core, 2GHz | 250GB SSD (NVMe) |
| MacMini | macOS 10.12.5 | i7-3615QM, 4-core, 2.3GHz | 1TB HDD (SATA) |
| Win-i7x4 | Win 10 Pro | i7-6820HQ, 4-core, 2.7GHz | 256GB SSD (SATA) |
| Win-AMDx8 | Win 10 Pro | Ryzen 1800X, 8-core, 3.6GHz | 250GB SSD (NVMe) |
Except for the Raspberry Pi3, most of these systems are fairly high end. Also to be noted is that Linux-AMDx8 and Win-AMDx8 have identical hardware. Same thing with Linux-i7x4 and Win-i7x4.
Other than that, all systems use stock configurations (without any particular tuning), except for the Win-i7x4 that had some (unfortunately unknown) 3rd party anti virus software installed.
The results
Creating threads
In this benchmark 100 threads are created. Each thread terminates immediately without doing any work, and the main thread waits for all child threads to terminate. The time it takes for a single thread to start and terminate is measured.
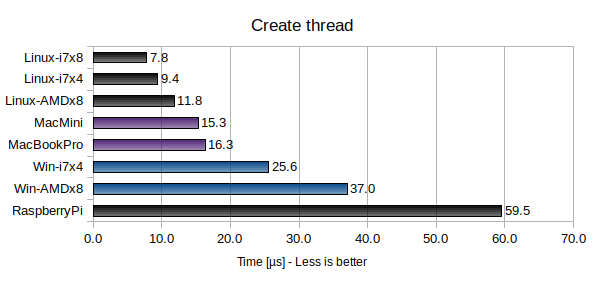 Apparently macOS is about twice as fast as Windows at creating threads, whereas Linux is about three times faster than Windows.
Apparently macOS is about twice as fast as Windows at creating threads, whereas Linux is about three times faster than Windows.
Creating processes
This benchmark is almost identical to the previous benchmark. However, here 100 child processes are created and terminated (using fork() and waitpid()). Unfortunately Windows does not have any corresponding functionality, so only Linux and macOS were benchmarked.
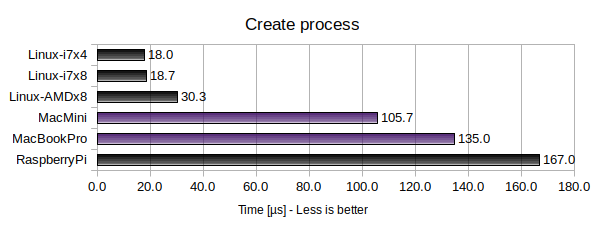 Again, Linux comes out on top. It is actually quite impressive that creating a process is only about 2-3x as expensive as creating a thread under Linux (the corresponding figure for macOS is about 7-8x).
Again, Linux comes out on top. It is actually quite impressive that creating a process is only about 2-3x as expensive as creating a thread under Linux (the corresponding figure for macOS is about 7-8x).
Launching programs
Launching a program is essentially an extension to process creation: in addition to creating a new process, a program is loaded and executed (the program consists of an empty main() function and exists immediately). On Linux and macOS this is done using fork() + exec(), and on Windows it is done using CreateProcess().
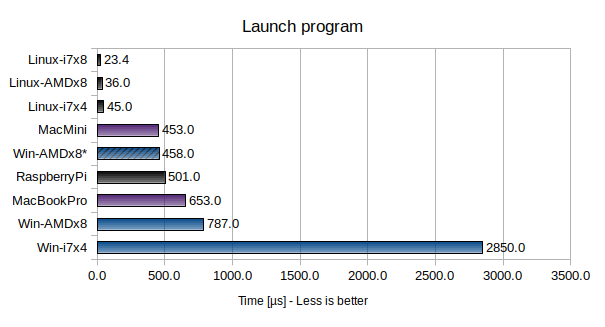 Here Linux is notably faster than both macOS (~10x faster) and Windows (>20x faster). In fact, even a Raspberry Pi3 is faster than a stock Windows 10 Pro installation on an octa-core AMD Ryzen 1800X system!
Here Linux is notably faster than both macOS (~10x faster) and Windows (>20x faster). In fact, even a Raspberry Pi3 is faster than a stock Windows 10 Pro installation on an octa-core AMD Ryzen 1800X system!
Worth noting is that on Windows, this benchmark is very sensitive to background services such as Windows Defender and other antivirus software.
The best results on Windows were achieved by Win-AMDx8*, which is the same system as Win-AMDx8 but with most performance hogging services completely disabled (including Windows Defender and search indexing). However this is not a practical solution as it leaves your system completely unprotected, and makes things like file search close to unusable.
The very poor result for Win-i7x4 is probably due to third party antivirus software.
Creating files
In this benchmark, >65000 files are created in a single folder, filled with 32 bytes of data each, and then deleted. The time to create and delete a single file is measured.
Here is where things get silly…
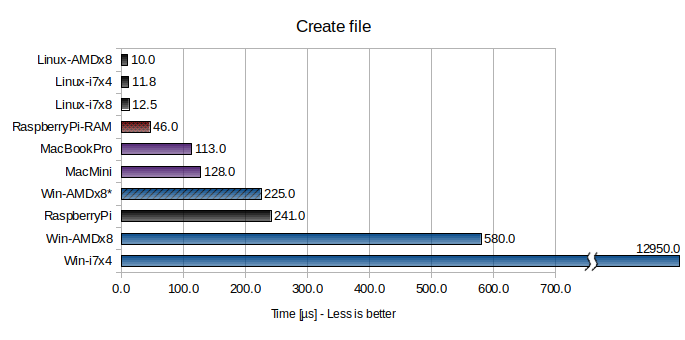 Again, Win-AMDx8* has Windows Defender and search indexing etc. disabled.
Again, Win-AMDx8* has Windows Defender and search indexing etc. disabled.
Two tests were performed for the Raspberry Pi3: with a slow MicroSD card (RaspberryPi) and with a RAM disk (RaspberryPi-RAM). For the other Linux and macOS systems, a RAM disk did not have a significant performance impact (and I did not try a RAM disk for Windows).
Here are some interesting observations:
- The best performing system (Linux-AMDx8) is over one thousand times faster than the worst performing system (Wini7x4)!
- Only with Windows Defender etc. disabled can an octa-core Windows system with a 3GB/s NVMe disk compete with a Raspberry Pi3 with a slow MicroSD memory card (the Pi wins easily when using a RAM disk though)!
- Something is absolutely killing the file creation performance on Win-i7x4 (probably third party antivirus software).
- Creating a file on Linux is really fast (over 100,000 files/s)!
Allocating memory
The memory allocation performance was measured by allocating 1,000,000 small memory blocks (4-128 bytes in size) and then freeing them again.
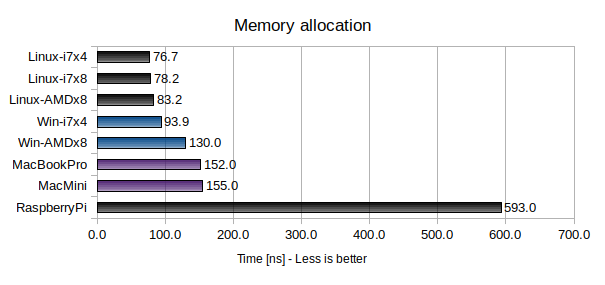 This is the one benchmark where raw hardware performance seems to be the dominating factor. Even so, Linux is slightly faster than both Windows and macOS (even for equivalent hardware).
This is the one benchmark where raw hardware performance seems to be the dominating factor. Even so, Linux is slightly faster than both Windows and macOS (even for equivalent hardware).
Conclusions
Some of the differences between the operating systems are staggering! I suspect that the poor process and file creation performance on Windows is to blame for the painfully slow git and CMake performance, for instance.
Obviously each operating system has its merits, but in general it seems that Linux > macOS > Windows when it comes to raw kernel and file system performance.
As a side note, I was quite surprised to find that Windows does not even offer anything similar to the standard Unix fork() functionality. This makes certain multi processing patterns unnecessarily cumbersome and expensive on Windows.
Any chance you could run the same tests on *BSD? OpenBSD and FreeBSD are of particular importance.
Unfortunately I don’t have a BSD setup, but if someone else does it would be very interesting to see the results. It should be easy to build and run the benchmarks (https://github.com/mbitsnbites/osbench).
Try disabling short filename creation on windows, should speed up the file creation bench a lot:
https://blogs.technet.microsoft.com/josebda/2012/11/13/windows-server-2012-file-server-tip-disable-8-3-naming-and-strip-those-short-names-too/
If you want to see some really ugly stuff, try benchmarking localhost performance (e.g Apache httpd on Linux vs. Windows serving cached files), even with SIO_FASTPATH enabled Windows is pretty surprisingly slow there.
Very interesting! I will at least try it on our build machines at work.
Update: I disabled 8.3 names but it had no effect on the benchmark results. The machine is still 20x slower than a nearly identical Ubuntu machine on creating files.
I’m sorry to say, but this kind of benchmark is useless. What are you benchmarking? OS? CPU Architecture? Hardware? Compiler? Filesystem? API? Disk? If you want to benchmark specific primitive of an OS, you need to use the same hardware in each case, and the same compiler (if possible, obviously, you can’t compile Windows kernel by yourself). Without it, there is no objective way to compare results.
That’s exactly what I was going to write! The Benchmark is useless because not a single parameter is constant except for the function/operation itself. You definitely have to test such things on the same hardware. You compare really outdated macOS hardware with relative new hardware for Linux and Windows. The idea of the benchmark is really good but please test it on the same hardware and repeat the test. That would be reallly interesting
I realize that most of the machines have different hardware, so in a way it’s a case of apples and oranges. The main reason is of course that I used whatever hardware I had access to. However, I believe that there is enough information in these benchmark results to deduct certain things. For instance, the slowest possible hardware (the Raspberry Pi) often outperforms both macOS and Windows.
Also note that two pairs of identical hardware are included in the test (“Win-i7x4″/”Linux-i7x4” and “Win-AMDx8″/”Linux-AMDx8”). macOS is trickier since it pretty much requires installing Linux and Windows on the Mac (which I’m not prepared to do on my private Macs).
Hi AdamK,
Useless? I don’t think so. Most time you evaluate system as whole (SO+Hardware), i.e: VPS. I use some benchmarks like these to test if the VPS is better or worse (general performance).
Of course that if you have a specific scenario is more accurate to test it than general benchmark but most of the time I’m looking for versatile systems where I can dedicate to a complete different task.
Regards
The next blog post should be about making Windows 10 perform at the same level as MacOS & Linux! Please?
From HN: ‘”Launching Programs” should use posix_spawn at least on macOS, it’s a distinct syscall there and faster than fork + exec.’
I was more interested in fork + exec, since that’s what’s used by CMake, Apache httpd, nginx etc.
the process modeling in windows is different from the *nix world. so CreateProcess is expenssive and unchangable
For these benchmarks to be most useful, you’d have to hold everything constant, as others have said. Also, we’d need to know a lot more about the SSDs. Just giving its capacity and interface isn’t enough. SSDs degrade over time, and can be very different depending on the amount of free space. Knowing the performance characteristics and situation with the SSDs will be critical.
And of course, the brand and model of SSD is important to know. A factor like that could easily explain these results. On Windows and Linux, it’s also important to know whose NVMe driver you’re using – the operating system’s default NVMe driver or the SSD vendor’s.
And you said: “The very poor result for Win-i7x4 is probably due to third party antivirus software.” That means you’ve got to get rid of that third-party AV software. That’s a major confound. I would just have a clean Windows 10 Pro system with Windows Defender as the AV.
Also, are the Linux installs server or desktop editions? If they’re servers, I’d compare to Windows Server 2016 if you can get access to a box or a cloud instance. In fact, maybe just testing all the server OSes (Ubuntu, Fedora, Windows 2016, the BSDs) on the same cloud service would be a good idea, because you could hold the hardware and hypervisor constant, probably.
I agree with the guy proposing BSD inclusion. That would be awesome. Here are FreeBSD optimization tips: https://calomel.org/freebsd_network_tuning.html
Thanks for the feedback Jose,
This post was really just a dump of my hobby measurements and findings since I thought that it could be of interest for more people. There are a lot of things going on in these figures, and sorting them out definitely needs more specific testing.
For instance, I find the “poor result for Win-i7x4” very interesting, since it indicates that AV software can have severe performance impacts. However we can’t really tell how much of an impact from these figures alone, but would need to dig deeper.
On other axes we have the impact of different file systems, different CPU performance, different disk performance, drivers and kernel versions etc, etc, all of which are interesting on their own, but would require more specific tests.
It would be very interesting to see people do more detailed investigations of these different aspects – unfortunately I do not have the time nor the resources to do it myself.
BTW, if you ignore all the results but the Linux-AMDx8 and Win-AMDx8 results, you will actually have identical hardware and age and a very clean/stock software setup.
As a side project I recently set up a clean dual boot Win 10 + Ununtu 18.04 machine with stock OS configurations to compare performance (this time I was looking at Git, CMake and GCC, and depending on the task Windows was 10%-1000% slower than Linux on the exact same hardware with the exact same software versions).
I think the fact that random antivirus software “seems” to be running on the Windows systems makes the whole thing not very useful. It’s also problematic that you don’t seem to actually *know* if there’s antivirus software running there? Or didn’t you check? It’s obviously crucial to the whole test.
All I know is that in everyday desktop performance, I don’t notice a huge speed difference between Windows 7 and a recent KDE neon on the same system. If anything, lots of operations are SLOWER on Linux (for example, copying large amounts of files between the Linux/Windows machine and a macOS machine over Samba — where Linux should drastically outperform Windows according to your benchmarks…)
The only thing where Linux really shines in comparison to Windows and macOS is the flexibility and configurability. Most other stuff (hardware support, stability, speed, software availability, coherence, etc.) is, unfortunately, still worse under Linux even in 2019. Though I’m still willing to sacrifice all of that for the gained flexibility and “open-ness”.
Regarding the antivirus software: It’s a valid point. I know that there was some antivirus software running on it, but I don’t know which one (it’s a company default machine installation). I could have thrown away the result (and of course you are free to ignore those results if you like), but for me it’s valuable information: you can get horrific performance if you don’t know how your system is configured.
Regarding Linux performance in general, these tests do not aim to benchmark regular desktop performance, but rather things that can affect disk- and process-heavy tasks that are common for software developers (such as using Git and compilers). Also, I have seen several benchmarks indicating that Linux is in fact faster for many raw compute tasks, such as Blender. E.g. see: https://youtu.be/cpE2B2QSsa0
I know this is a really old post – but I was admiring your recent risc/vector architecture posts and ran across this.
I was specifically looking at thread creation but I’m sure all could use modification based on:
QueryPerformanceCounter is a pig, do not use it inside any performance-sensitive loops. When I removed it the thread create time was difficult to measure on Windows.
Rewrite these to not use QueryperformanceCounter and republish – maybe use GetTickCount64 which returns milliseconds since turned on. You will see a huge difference.
Maybe measure at the start and at the end of a single loop with a 100,000 thread create/ends run 100 at a time…
File creation benchmarks should be on an exFat partition so it is comparable.
Here is postgres implementation of gettimeofday
https://git.postgresql.org/gitweb/?p=postgresql.git;a=blob;f=src/port/gettimeofday.c;h=75a91993b74414c0a1c13a2a09ce739cb8aa8a08;hb=HEAD
I understand the critics to this benchmark, but it DOES make a difference: using Git and Emacs with Magit on Windows is unbearably slow. Actions that are instantaneous on Linux take seconds (more than 10 seconds even for simple repositories).
Of course one could argue that “these applications are badly ported to Windows”. Well, no I disagree. These applications are built on the assumption that these features are fast, and Windows is so slow that makes them unusable. This is a fuck-up of the OS, not the application designer.
Granted, if you were to design a Windows application from scratch, you would workaround these issues by using different mechanisms and methods to ensure your app performs well enough; in other words, you would be making architectural decisions based on the performance limitations of the underlying OS.
> On Linux and macOS this is done using fork() + exec()
Try vfork or posix_spawn. Should be even faster.